Board Games Buddy
Partie 2: Ambition, Architecture et Design
Le but de ce projet tient plus dans la réalisation d’une plateforme générique pour jeux de société que dans l’implémentation ou l’étude du meilleur algorithme qui soit dans ce domaine. Il est donc important de bien définir les contraintes que l’on se donne pour esquisser la solution en conséquence.
Bien sûr, la performance des IA est capitale dans la mesure où il n’est pas intéressant de se confronter à un adversaire trop faible. Mais nul n’est besoin ici d’égaler les performances stratosphériques des meilleurs programmes dédiés (par exemple comme pour le go ou les échecs). Il serait d’ailleurs difficile de tenter d’égaler certaines solutions existantes du fait de l’importante puissance de calcul nécessaire pour l’entrainement des réseaux de neurones utilisés.
An engine to play them all
Ce que je désirais surtout dès le départ c’était de disposer d’une solution sur laquelle pouvoir implémenter toutes sortes de jeux de société, sachant que ceux-ci peuvent incorporer de nombreux mécanismes comme le hasard, des informations cachées, des ordres de tours qui peuvent changer selon les circonstances, des actions où les joueurs effectuent des choix simultanés, etc. Il était donc nécessaire d’embrasser tous les mécanismes communs aux jeux de société avec la seule restriction de se limiter aux jeux au tour par tour.
Même si nous n’aborderons pas le sujet des IA tout de suite, il était clair dès le début qu’il faudrait se frotter à un moment ou un autre à l’entrainement de réseaux de neurones pour les algorithmes qui reposent sur ce genre de mécanismes. Cela implique de pouvoir collecter facilement des données d’apprentissage sur des parties où la machine s’affronte elle-même.
Enfin, il était important pour moi d’avoir la possibilité que les jeux puissent se jouer dans un navigateur Web au travers d’une interface graphique agréable, mais sans que le code tourne intégralement côté client.
Ces contraintes sont quelque peu différentes des nombreux projets ou tutoriels que l’on peut trouver dans le domaine des jeux de société. La solution OpenSpiel développée par DeepMind, par exemple, est fortement axée sur la recherche. Elle a pour vocation d’implémenter un maximum d’algorithmes et d’outils permettant de couvrir l’état de l’art, mais nécessite de savoir quoi utiliser et comment et ne propose aucune interface graphique. Quant aux nombreux tutoriels que l’on peut trouver sur le Web, ils ne se préoccupent habituellement que d’un seul jeu ou d’un seul type d’algorithme, laissant de côté les performances ou la généricité.
De mon côté, je me suis plutôt orienté vers une solution bâtie sur trois composants:
- Une libraire ayant la charge d’implémenter la logique générale, les IA, ainsi que les mécaniques fines de chacun des jeux de société;
- Un serveur encapsulant la librairie et permettant de faire tourner celle-ci sur une machine distante au travers d’une API dédiée;
- Le client Web se chargeant du rendu des jeux dans un navigateur.
Cela permet beaucoup de souplesse dans l’utilisation finale, comme illustré dans la figure de déploiement ci-dessous.
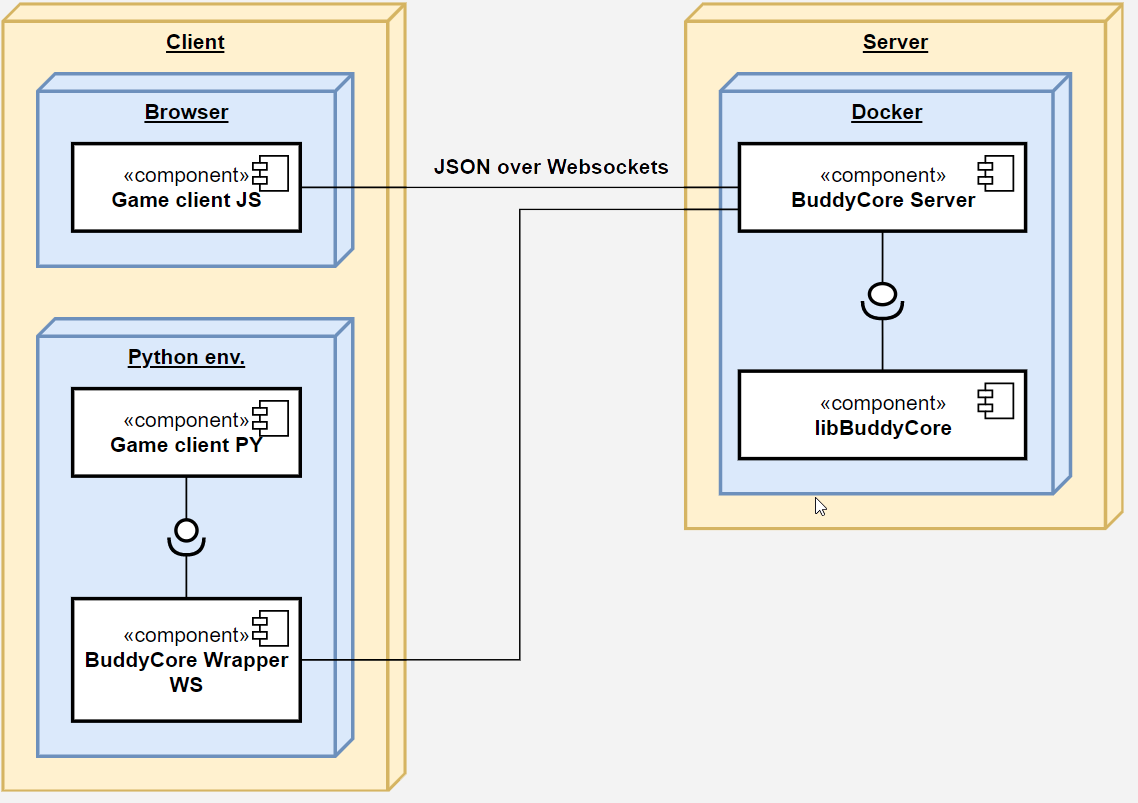
La partie droite contient ladite libraire libBuddyCore, ainsi qu’une application BuddyCore Server exposant son utilisation au travers d’un moyen de communication basé sur les Websockets. Le protocole WebSockets m’a paru la solution de choix dans la mesure où il offre toute la flexibilité d’une communication bidirectionnelle TCP/IP, mais est également compatible avec tous les navigateurs Web. La bidirectionnalité est importante afin que le serveur puisse envoyer toutes les notifications qui surviennent lors d’une partie (les coups sélectionnés, des statistiques, des requêtes, etc.) de son plein gré, évitant ainsi le recours à du polling intempestif. Le contenu des messages , quant à lui, est construit en JSON, car ce format à le grand avantage d’être lisible et cela facilite considérablement le développement. Recourir à un encodage plus compact n’a pas lieu d’être ici vu le faible débit des messages échangés durant une partie.
La portion de gauche illustre deux façons de s’interfacer avec le serveur. La première, dont j’ai parlé plus haut, est un client Web se chargeant de la communication avec le serveur, du déroulement générique d’une partie, ainsi que du rendu graphique propre à chaque jeu. Pour information, le rendu est effectué en dessinant dans un canevas HTML5 et j’ai été agréablement surpris par la facilité, la qualité et la fluidité avec laquelle il est possible d’y arriver. N’ayant jamais programmé en JavaScript auparavant et ayant plutôt l’habitude des applications graphiques natives, c’était honnêtement une bonne surprise. Ensuite, il est bien sûr imaginable de s’interfacer avec le serveur au moyen de n’importe quel autre langage, comme illustré avec la partie Python dans le bloc inférieur.
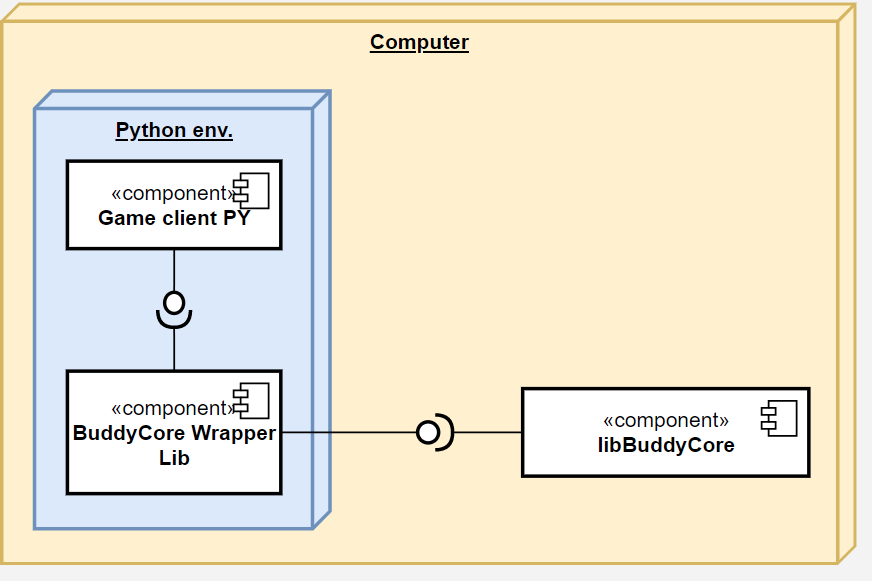
Si cette séparation entre client et serveur est très intéressante pour un déploiement réel de l’application, cela complexifie aussi les opérations. Il est toutefois possible de faire un usage beaucoup plus commode de la libraire en s’interfaçant directement avec elle, comme illustré dans l’image ci-dessous. C’est de cette façon que la librairie est utilisée pour effectuer des tests ou pour collecter des données en grande quantité pour l’entrainement de réseaux de neurones.
A chaque tâche son langage
Une fois les grandes lignes de l’architecture posées vient la question des langages à employer pour développer les différents composants. La partie graphique tournant dans un navigateur est alors la plus simple à trancher, car il n’existe que peu ou pas de choix en dehors du JavaScript. L’entrainement de réseaux neuronaux impose de passer par des librairies telles que TensorFlow ou PyTorch, lesquelles sont principalement utilisées en Python. Toutefois, l’entrainement des algorithmes d’IA constitue une tâche qui s’effectue seulement en marge et qui n’a pas d’incidence ensuite sur l’utilisation finale.
Le point le plus important concerne alors le choix du langage pour la librairie libBuddyCore. Celle-ci a pour but d’implémenter efficacement toutes sortes d’algorithmes d’IA et qui, on s’en doute bien, doivent pouvoir être exécutés le plus rapidement possible tout en offrant une gestion de la mémoire très efficace. La raison impérieuse nous obligeant à nous concentrer sur l’efficience vient du fait que ces algorithmes sont par nature très couteux en temps de calcul et en mémoire. Réfléchir au prochain coup à jouer revient en effet d’une manière ou d’une autre à évaluer un maximum de possibilités afin de sélectionner la plus prometteuse. Un algorithme tournant deux fois plus vite peut donc explorer autant de choix en plus endéans le même laps de temps. C’est aussi un algorithme qui pourra effectuer deux fois plus vite un même nombre de parties contre lui-même pour collecter des données d’apprentissage. De la même façon, un algorithme requérant deux fois moins de mémoire pourra d’autant plus facilement être parallélisé pour gagner encore en vitesse d’exécution.
Ces considérations étant établies, il est évident qu’aller vers un langage interprété tel que le Python, pourtant très prisé dans le domaine scientifique, reviendrait à se tirer une balle dans le pied. Son inaptitude à exécuter du code parallélisé, sa lenteur rédhibitoire dès que l’on écrit la moindre boucle (environ 2 ordres de grandeur par rapport à du code natif) et son manque de contrôle sur la gestion de la mémoire font vraiment de lui l’un des pires candidats auquel on puisse penser. Ensuite, si un langage intermédiaire comme le Java peut faire l’affaire, il est beaucoup plus intéressant de se tourner vers un langage compilé pour tirer profit au maximum des capacités de la machine hôte. Si plusieurs choix sont certainement valables, je me suis orienté vers le C++ tout simplement à cause de mes décennies d’expérience dans ce langage.
C’est alors à ce stade que le Python que l’on avait sorti par la porte peut faire son retour en passant par la fenêtre. Si l’on se donne la peine d’encapsuler la libraire native dans un “wrapper” Python, celle-ci peut ensuite s’utiliser en bénéficiant de toute la facilité propre à ce langage, tout en conservant des performances inchangées. Il s’agit là d’un combo gagnant que l’on retrouve dans beaucoup de projets, TensorFlow en étant un parfait représentant.
Dans les entrailles de la bête
La partie la plus complexe dans ce projet tient certainement dans la fameuse librairie libBuddyCore, puisque c’est à elle que revient l’honneur d’intégrer les différentes IA et d’offrir une interface permettant de faire complètement abstraction des jeux que l’on pourra y implémenter. Comme nous aborderons les IA dans les prochains chapitres, concentrons-nous ici sur l’implémentation générique d’un moteur de jeux de société.
Abstraction des jeux
Le diagramme de classes de la partie concernant l’implémentation des jeux est donné dans l’image ce-dessous:
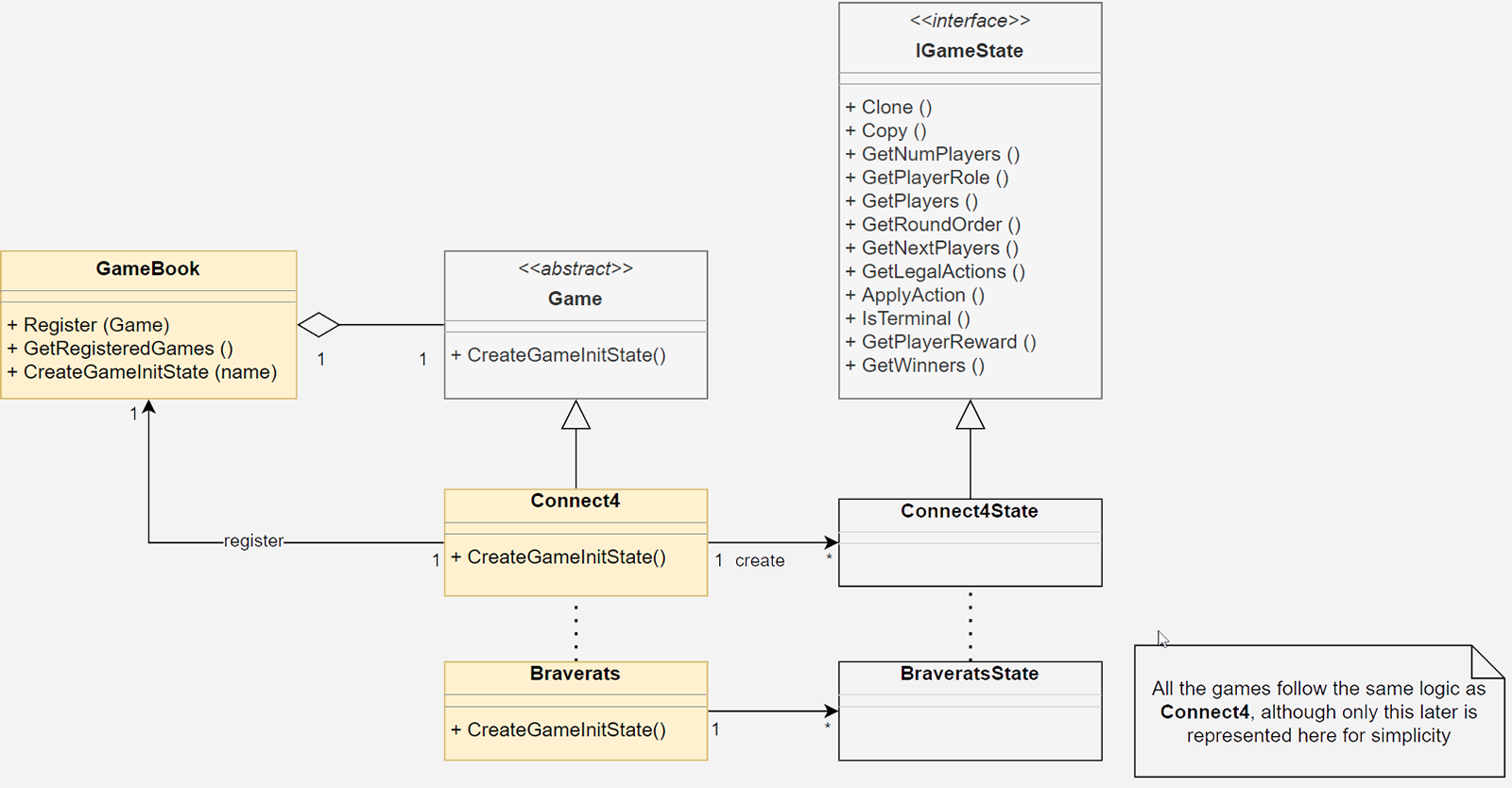
Afin de pouvoir exposer une interface simple concernant les jeux disponibles, la librairie gère tous ceux-ci au travers du Singleton GameBook. Ce dernier dispose d’une liste de jeux qui se font connaitre par leur interface abstraite Game, comme c’est le cas par exemple pour la classe Connect4. La fonction principale de la classe Game est la méthode CreateGameInitState qui, comme son nom l’indique, permet d’instancier l’état initial du jeu qu’elle représente.
L’état de n’importe quel jeu, c’est-à-dire l’ensemble des informations qui sont nécessaires pour connaitre la disposition de tous ses éléments de gameplay à un instant donné, est exposé au travers de la classe abstraite IGameState. Cette dernière dispose d’un jeu de fonctions génériques permettant de le manipuler afin de faire avancer le cours d’une partie. Étant donné que les actions possibles dépendent intégralement du jeu dont on parle, il est obligatoire d’abstraire ces dernières de la même façon. Aussi, une action sera toujours représentée par une valeur entière dont la signification est laissée à la totale discrétion du jeu. Par exemple, les actions du jeu Puissance 4 peuvent être représentées par les nombres de 1 à 7 pour désigner chacune des colonnes dans lesquelles jouer un pion. Mais toute autre numérotation ferait l’affaire.
La fonction GetLegalAction retourne donc systématiquement une liste de nombre abscons et ceux-ci peuvent être dépendants de l’état du jeu lui-même. La fonction ApplyAction permet ensuite de faire évoluer l’état du jeu en fonction du numéro d’action passé en argument, mais encore une fois cet aspect est laissé à la discrétion du jeu lui-même. Il s’en suit que les informations qu’une IA peut glaner sur l’évolution d’une partie seront toutes aussi abstraites et se résument à
- des numéros d’actions disponibles;
- le numéro du joueur dont c’est le tour;
- un score intermédiaire éventuel;
- si la partie est terminée et, si oui, qui est le vainqueur.
Il apparait ainsi clairement que ce moteur de jeu n’est pas conçu pour implémenter des IA spécifiques aux jeux disputés, mais plutôt pour des IA générales qui pourront joueur à toute une classe de jeux partageant les mêmes propriétés de très haut niveau.
Orchestration d’une partie
Le diagramme ci-dessous reprend les principales classes impliquées dans le déroulement d’une partie entre multiples agents, encore une fois sans avoir connaissance du détail des agents ou des jeux. Le point de contact avec l’extérieur de la librairie est constitué de la classe Contest qui a la charge de rassembler un ou plusieurs agents autour d’une partie. Ceux-ci doivent tous hériter de la classe abstraite Agent et il existe également un agent spécial pour s’interfacer avec l’extérieur de la librairie, afin de permettre à un joueur humain ou à une IA externe de prendre part à la partie.
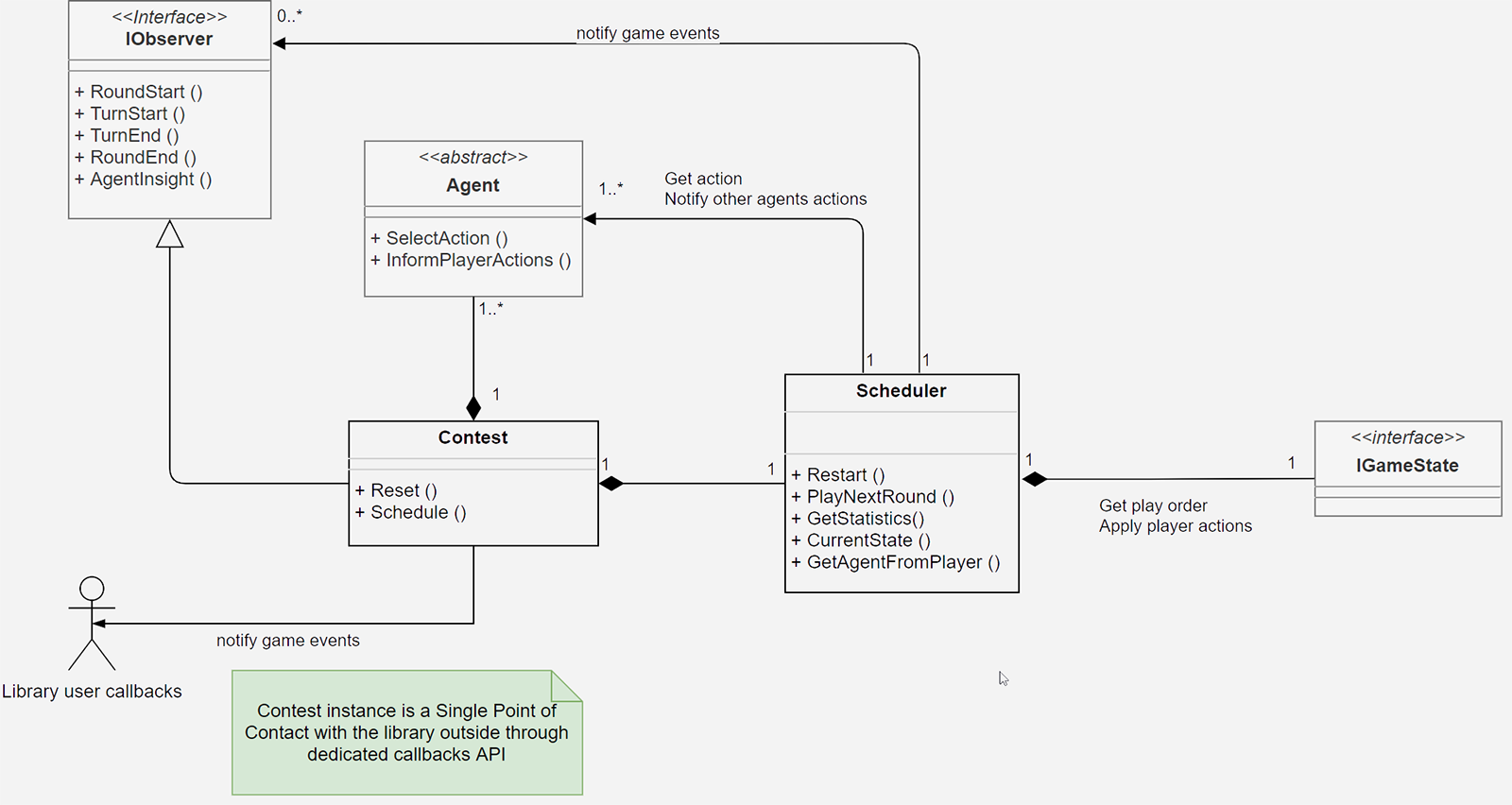
Le déroulement précis d’une partie est laissé aux soins de la classe Scheduler qui a pour rôle :
- de s’informer de l’ordre dans lequel doit jouer chaque agent,
- de collecter la liste des actions qui sont accessibles à chacun d’eux,
- de leur communiquer cette liste,
- de prendre connaissance en retour de l’action sélectionnée,
- de transmettre cette action au jeu afin de faire évoluer son état,
- de signaler aux agents le nouvel état du jeu,
- de signaler toutes ces étapes pour tenir informer l’utilisateur de la libraire du déroulement de la partie.
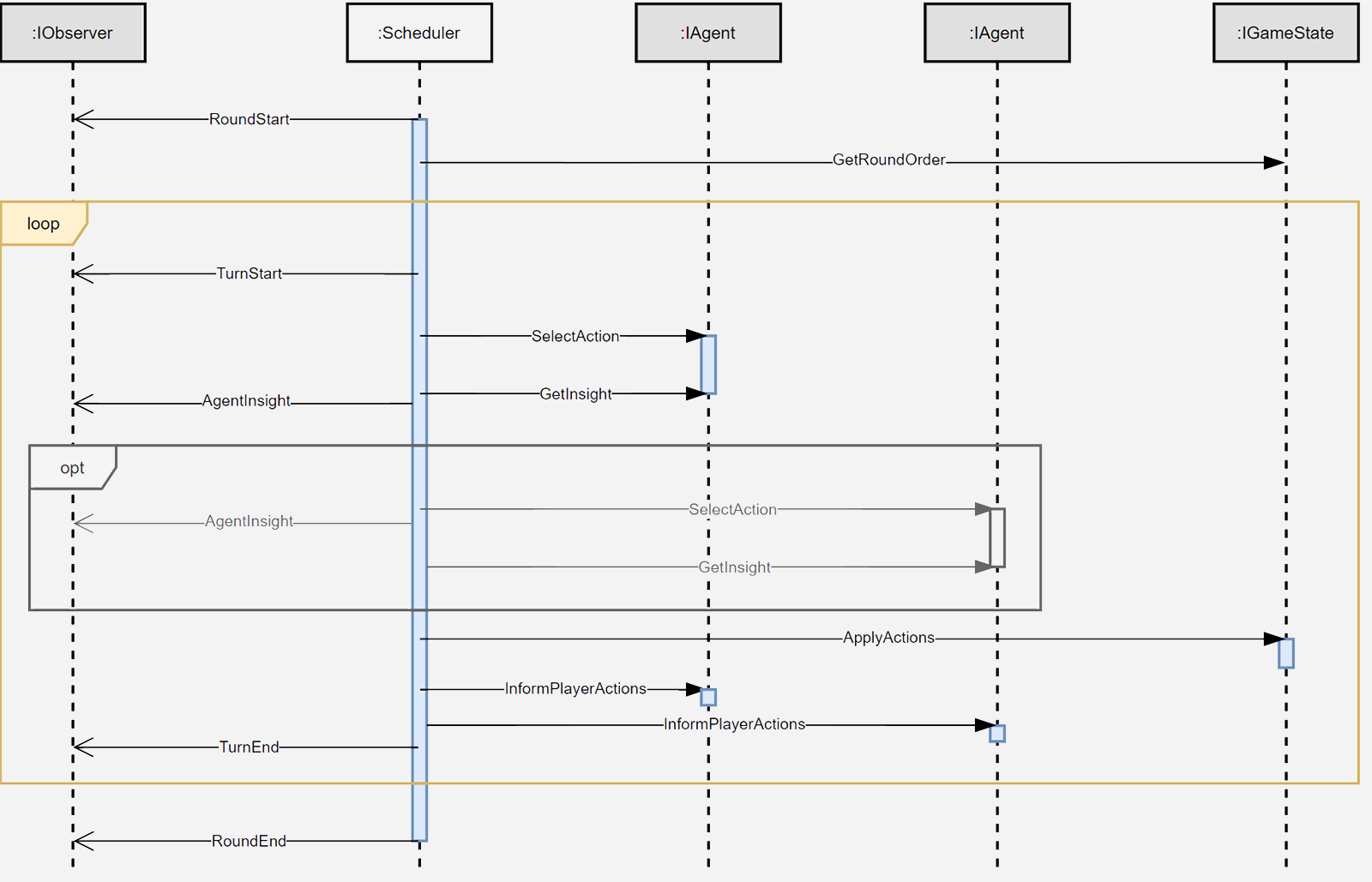
Ces différentes étapes sont illustrées plus en détail sur le diagramme de séquence ci-dessous. Afin de s’accommoder à toutes sortes de schémas pouvant survenir dans un jeu de société, une partie est découpée en une succession de Rounds, eux-mêmes organisés en un enchainement de Turns.
L’idée d’un Round est très proche de celle que l’on retrouve traditionnellement dans un jeu, c’est-à-dire qu’il donne l’occasion à chaque joueur de jouer une fois. Cela n’est toutefois pas obligatoire, certains joueurs pouvant très bien devoir passer leur tour ou jouer plusieurs fois. Un Turn, quant à lui, permet à un ou plusieurs joueurs de jouer simultanément. Concrètement, aucun agent n’est informé du choix des actions des autres et de l’état résultant du jeu tant que cette phase n’est pas complètement résolue. Si aucun choix simultané n’est nécessaire, un Turn n’impliquera qu’un seul agent.
Le contenu d’un Round n’est aucunement figé, car c’est le jeu lui-même qui décide de son contenu avant qu’il ne commence. Il peut donc être remanié au besoin en fonction des circonstances et permettre ainsi des schémas complexes. Dit autrement, une instance IGameState peut décider à chaque Round de l’ordre précis des joueurs, tandis que la classe Scheduler orchestrera la partie en conséquence pour faire transiter toute l’information entre les parties prenantes.
Conclusion
Ce chapitre a été l’occasion de définir les objectifs de haut niveau de ce projet et de survoler les choix principaux de conception qui ont été mis en oeuvre pour les atteindre. Le prochain chapitre rentrera plus dans le vif du sujet en commençant à aborder une problématique qui a été éludée jusqu’ici: la réalisation concrète d’une IA.